1. Network architecture
This guide provides step-by-step instructions for deployment of MiaRec call recording software on Amazon AWS.
MiaRec on AWS can leverage many of the services that are designed with High Availability. Depending on anticipated capacity, we recommend two types of HA architecture:
- Basic HA with two EC2 instances in all-in-one configuration (*). Recommended for up to 2,000 subscribers.
- Advanced HA with dedicated EC2 instances for each of components. Recommended for more than 2,000 subscribers.
(*) All-in-one configuration means recorder, database, web application and other components are hosted on the same virtual server.
This guide describes the Basic HA setup for recording of up to 2,000 subscribers. The recommended network architecture for MiaRec on AWS is shown in the following diagram.
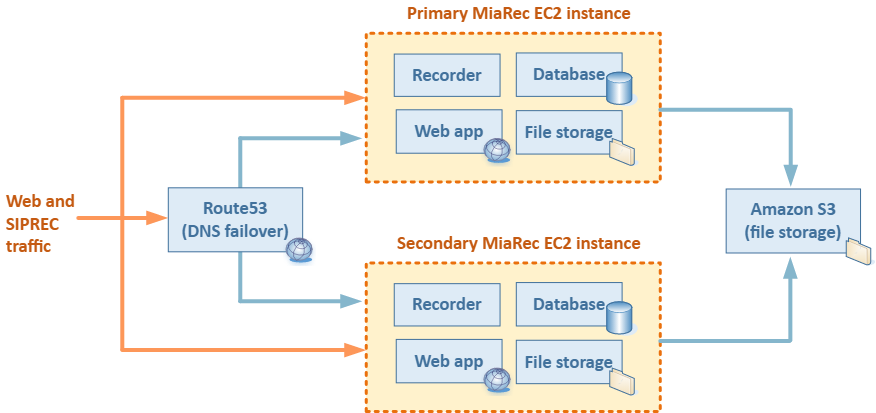
Components:
- Two EC2 instances (Virtual Servers) hosting MiaRec software in all-in-one configuration.
- S3 (Cloud Storage) for long term storage of recorded audio/video files.
- Route 53 service (Managed Cloud DNS) for DNS failover
High Availability characteristics:
- Server Redundancy. In the proposed architecture, we have two independent MiaRec servers (EC2 instances). These instances are configured in Hot Standby mode. When the primary server fails, the secondary server is switched into operation. The instances are deployed in different Availability Zones (covered in this guide) or Regions.
- Data Redundancy. Configuration and call metadata is stored in database. The recorded files are stored in file system. Database data is replicated asynchronously between two MiaRec instances. The audio/video files are uploaded to Amazon S3 storage, which provides replication and redundancy.
- Auto Failover mechanism. Amazon Route 53 service monitors the health and performance of MiaRec instances. Using DNS failover, it can route the web traffic from an unhealthy instance to a healthy one. For SIPREC traffic, we recommend to use DNS SRV-based failover if the phone platform supports it (DNS SRV-based failover will minimize downtime). If DNS SRV is not supported by phone platform, then it is possible to use Router 53 DNS failover mechanism for SIPREC traffic.
Frequently asked questions:
Why not use DNS round-robin for web traffic load balancing?
Round Robin DNS works by responding to DNS requests with a list of potential IP addresses corresponding to several web servers that host identical resources. The DNS server returns a list of IP addresses in random order.
DNS round robin works the best for load balancing. Failover scenarios are not recommended due to how browsers handle multiple addresses. Modern browsers will choose one of IP addresses and if it cannot connect, the browser will try the next server. the process is user-transparent, and occurs only if the first server tried times out, and only for the first page requested from our site in any browser session. If one of the servers is down for long time, then 50% of users will receive its IP address the first in a list, they will experience high load time (about 3 minutes) for the first page. Older browsers (like IE7) do not support switching to the second IP address, i.e. 50% of users on old browsers will not be able to access the web server (many web-sites today do not support old web browsers, so, this fact probably can be ignored).
Another drawback of DNS round robin technique comes from how MiaRec replicates data between instances. DNS round robin works the best with stateless servers. In this guide, we build stateful MiaRec server, which includes database in the same machine. Data between machines is replicated asynchronously. Asynchronous replication has a lot of advantages comparing to synchronous replication, but there is the expected delay in data synchronization. For example, MiaRec synchronizes only the completed calls. The in-progress calls will be visible on of servers only. If using DNS round robin, then 50% of users will not be able to see in-progress calls.
DNS SRV vs DNS failover for SIPREC traffic
If the phone platform supports DNS SRV for SIPREC, then it should be used as a preferred method. With DNS SRV, the phone platform receives a list of IP-addresses with priorities. The IP-addresses will be tried in particular order depending on record priority/weight. If one of servers does not respond, then the second one will be tried automatically.
The phone platform determines that server is not available based on its SIP response. DNS SRV-based failover time is shorter than DNS failover. The Amazon Route 53 DNS failover uses health checks, which are good for web servers, but they cannot check health of SIP devices.
Depending of implementation, the phone platform can preemptively monitor each of IP-addresses using SIP keep alive mechanism (usually, send SIP OPTIONS message) and make failover time even shorter.
Why upload audio/video files to S3 instead of storing them locally on EC2 instance?
Short answer: costs and reliability.
According to official documentation "Amazon EBS volumes are designed for an annual failure rate (AFR) of between 0.1% - 0.2%, where failure refers to a complete or partial loss of the volume, depending on the size and performance of the volume." Amazon S3 is designed to deliver 99.999999999% durability (documentation).
Amazon EBS volume data is replicated across multiple servers in an Availability Zone. With Amazon S3 data is automatically distributed across a minimum of three physical facilities that are geographically separated by at least 10 kilometers within an AWS Region, and Amazon S3 can also automatically replicate data to any other AWS Region.
EBS costs are $0.10 per GB/month (US East Region, General Purpose SSD). S3 storage costs are $0.023 per GB/month (US East Region, first 50TB).
How to scale this architecture?
The architecture described supports vertical scaling, i.e. the EC2 instance can resized to larger CPU/memory values. You must stop your Amazon EBS–backed instance before you can change its instance type.
How big is a delay in synchronization between servers?
Data is replicated asynchronously. The replication process can be configured to start either by schedule or continuously. In the latter case, call recording metadata and file will be replicated as soon as call completes. Other configuration data, like users/groups/roles will be replicated as soon as the next recording is replicated or up to 1 minute after a change, if call traffic is low.
What happens if the primary server is down?
This is probably the most important question in this guide.
When the primary server is down, then failover mechanism is initiated. Amazon Route 53 service monitors the health and performance of MiaRec instances. If it detects that one the primary server is unhealthy, then DNS records are updated to point to the secondary server. The web traffic will be automatically loaded to the secondary server.
Failover for SIPREC traffic is managed independently of web traffic failover. The phone platform reds a list of IP addresses of recording servers from DNS SVR record. It automatically route SIPREC traffic to the secondary server if the primary server doesn't respond to SIP requests.
If the server is down completely, then both SIPREC and web traffic will be automatically routed to the second instance. This scenario is straight forward. But there is a potential situation when only one of software components experiences issues. For example, web server is not responding on the primary server, but recorder service is fully functioning. In this case, the failover occurs only for web traffic. Such loosely coupled architecture (independence in web and siprec failover events) has some pros and cons. Good thing in MiaRec architecture is it allows the recorder service to continue recording of calls even if other components, like database and web server are completely down. This guarantees that the most critical part of call recording platform is as robust as possible. If, for example, both servers experience problems with the web component, the recording process is not affected at all. In order to detect such enormous situations with partial failure, it is necessary to utilize monitoring tools like CloudWatch, Zabbix or similar.
How much data may be lost in case of primary server is down?
Data between servers is replicated asynchronously by schedule or continuously. In the later case, call metadata will be uploaded to other server as soon as call completes.
If there were in-progress call recordings on the primary server before it died, then such calls will be recorded only partially. If disk storage of the primary server is recovered later, then it is possible to recover the first portion of media for such in-progress calls. The replication process will be restored automatically after the server is alive again.
If the disk storage of the primary server is unrecoverable, then data for in-progress recordings as well as data of not-uploaded yet recordings is lost.