MiaRec multi-master asynchronous replication
MiaRec solution implements data replication with the following characteristics:
- Multi-master
- One-way, two-way or N-way
- Asynchronous
- Application-level
- GEO distributed
- Continuous, manual or scheduled
- Auto resume after network breakdown
This articles describes in details each of these characteristics and compares MiaRec solution with alternatives. The competitive solutions are built usually on file-storage based replication and have a number of weaknesses discussed below.
How it works
When recording of each individual call is completed, MiaRec pushes it into queue for automatic replication to other server(s) in a cluster. Such data replication may be started immediately upon call completion or scheduled to specific time of day (for example, at night).
Besides replication of call recordings, MiaRec replicates also user data in one-way or two-way directions. The updates to user data is automatically uploaded to other servers in a cluster.
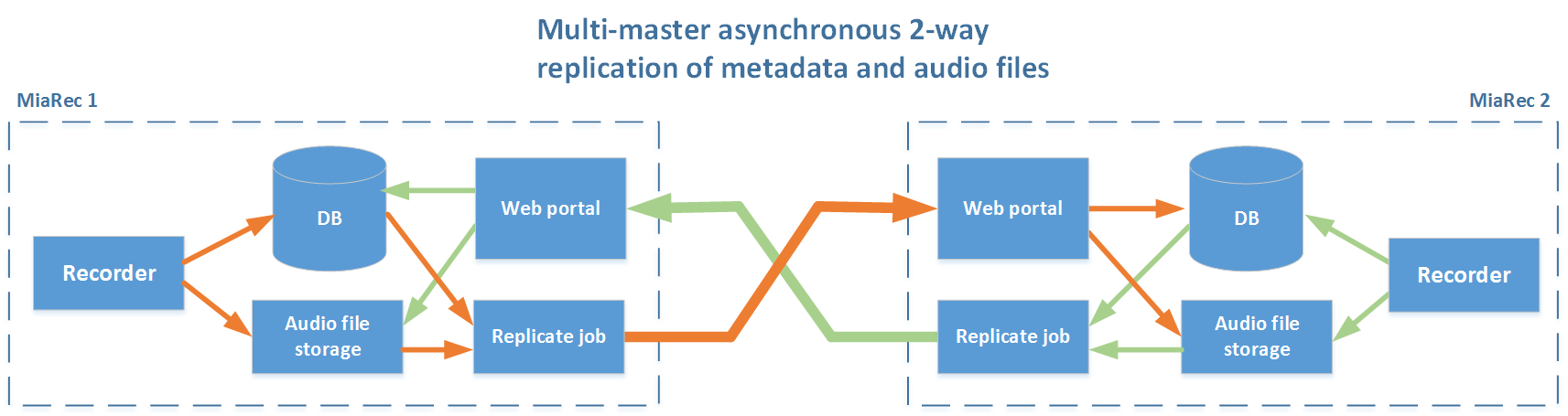
Replication architecture of MiaRec has the following characteristics:
- Multi-master. Any of servers in a cluster can be used for recording tasks at any time. It is possible to use multiple recorders simultaneously for load balancing purposes.
- Asynchronous replication. Data is replicated asynchronously. Data synchronization can be triggered by schedule (once per hour/day/week) or continuously upon each individual call completion. It works seamlessly in GEO-redundant architecture when datacenters are located too far from each other. In a contrast, other solution may use synchronous replication, which require low latency (less than 5ms) connection between datacenters, this is equal to maximum 100km distance between servers. With a synchronous replication, if a link between datacenters is down even for 1 second, the redundant server is removed from a cluster and manual re-synchronization is required between servers. Automatic restore of cluster is not possible by design with synchronous replication.
- Application-level replication. MiaRec implements replication internally on application level. It has a few advantages: cost, easy management and selective replication. In a contrast, other solutions may use replication on database level or disk level (SAN). SAN replication is supported only in highly expensive enterprise SAN disk arrays. In both of these competitive solusions (database replication and SAN replication) the selective replication is not supported.
Multi-master vs master-slave replication
| Multi-master replication (MiaRec) | Master-slave replication (other vendors) |
|---|---|
All servers run as master servers, thus you can record calls on any of servers at any time or even simultaneously to multiple servers. This makes system highly flexible in a way that any operation can be processed in any server which enables better load balancing. However, such flexibility brings the challenge of keeping servers consistent. A conflict occurs if more than one server tries to update the same object. In MiaRec we solved this issue with the following mechanisms:
|
In master-slave replication, there is only one server in the system which is capable of recording data. All other replicating servers are called slaves and can only accept read-only requests. In master-slave replication, the master server becomes overwhelmed and system suffers from scalability due to using a single server for write operations (call recording). Setup of automatic fail-over mechanism can be tricky. When master server becomes unavailable, one of the slaves can be promoted as a master. When the master server is back, it usually stays in off-line mode and requires manual re-synchronization of servers to assure data consistency. Such synchronization process is quote time consuming and it is recommended to have at least 3 servers in a cluster (1 master and 2 slaves) in order to avoid single point of failure situations while master server is in off-line mode. If such configuration is used in GEO-redundant setup, it may create too much burden to administration staff in case of frequent issues with connection between datacenters. |
Asynchronous vs synchronous replication
| Asynchronous replication (MiaRec) | Synchronous replication (other vendors) |
|---|---|
In asynchronous replication, an incoming request is processed and get committed on the receiving server without propagating it to other replicating servers simultaneously. Instead, committed request are deferred and sent to all other replicating servers asynchronously. Once replicating servers receive these deferred request, they process them and make themselves synchronized. Asynchronous replication utilizes network resources intelligently, creates less traffic, and provides higher performance. Deferring multiple request and propagating them all as a big chunk of requests is much more efficient rather than to propagate each of them separately. Operation latency is reduced as opposed to synchronous replication because a server can go ahead and process a request without need to talk with other servers to commit it. It also provides better scalability since response time of a server is independent from the number of replicating servers, and generated network traffic is proportional to the number of replicating servers. Moveover, network latency introduced due to the geographical distance between replicating servers can be tolerated and hidden since requests are deferred and propagated asynchronously. Additionally, asynchronous replication can be scheduled to execute during less busy hours, like at night or weekends. |
In synchronous replication, incoming requests are propagated to and processed by all replicating servers immediately. The benefits of synchronous replication is to guarantee that data is consistent at all servers at any time. While propagating requests and synchronizing servers, two-phase commit protocol is used. When a request comes in a sever, the same request is also forwarded immediately to all replicating servers. All servers have to process incoming request to see if it is OK to be committed, and have to inform the propagating server in this regard. If and only if all replicating servers inform that request can be committed, then second message is propagated to commit the request in all replicating servers. If any replicating server complains about the request, than abort message is propagated and all servers have to disregard the request. Although it ensures that replicating servers are synchronized immediately when a request is committed and prevent consistencies may occur otherwise, it generates huge network traffic due to high number of sends and receives to decide to commit or abort. It increases processing latency which degrades operation performance since operation has to wait until all replicating servers have been synchronized. Scalability also suffers from increasing number of replicating metadata servers that tend to create exponentially growing network traffic and processing latency that ends up with longer response time. Synchronous replication is not suitable for GEO-redundancy when distance between datacenters is more than 100km. |
Application-level vs Storage array-based replication
| Application-level replication (MiaRec) | Storage array-based replication (other vendors) |
|---|---|
MiaRec replication mechanism is based on knowledge of data. This allows it to selectively replicate only the necessary data. For example, administrator may enable continuous (as soon as possible) replication for call recording data and for the rest of data (like logs) schedule replication during off-hours (at night, for example). Additionally, it is possible to set filtering criteria for replication. For example, replicate only call recordings of particular tenant(s) or group(s). Having knowledge of data allows MiaRec application to resolve conflicts intelligently. For example, if the same user record is updated from multiple servers simultaneously, then administrator may decide to resolve conflicts automatically based on priorities or manually. In a contrast to storage array-based replication (SAN), MiaRec replication mechanism supports any storage, like NAS, local, virtual environment. It doesn’t depend on hardware. It is possible to mix different storage types in the same clustomer, for example, replicate form local or NAS storage to SAN. MiaRec application-level replication supports multi-master architecture, which is not possible with a storage array-based replication. As a result, utilization of hardware is much better due to using second storage in load balancing configuration. MiaRec supports also replication to multiple servers simultaneously. Application-level replication is tolerant to temporary problems with a link between replicating servers. In case of problems with a link between datacenters, MiaRec replication process is postponed and automatically resumed when link is restored. No data loss occurs due to in this case. |
Storage array-based replication is expensive. Usually it is available only in enterprise SAN disk arrays. It doesn’t have knowledge of data that is stored on disk. As a result, it is not possible to configure selective replication. You need to replicate an entire SAN or nothing. Storage array-based replication works only for a pair of SAN arrays of exactly the same vendor/model and size. It is not possible to mix SANs from different vendors or even different models of the same vendor. SAN replication usually supports both asynchronous and synchronous replication, but the latter is not suitable in GEO-redundant environment because it works only for a distance up to 100km between datacenters. When using SAN replication in asynchronous mode, it suffers from ineffectiveness of investments. One of SAN-arrays in a pair is used in passive mode most of the time until disaster occurs. In case of DR, a switch from primary SAN to the secondary usually occurs automatically, but a reverse operation requires the manual intervention of human. In case of problems with a link between datacenters, data on primary and secondary SAN arrays becomes inconsistent and requires manual re-synchronization, which is very time consuming. |