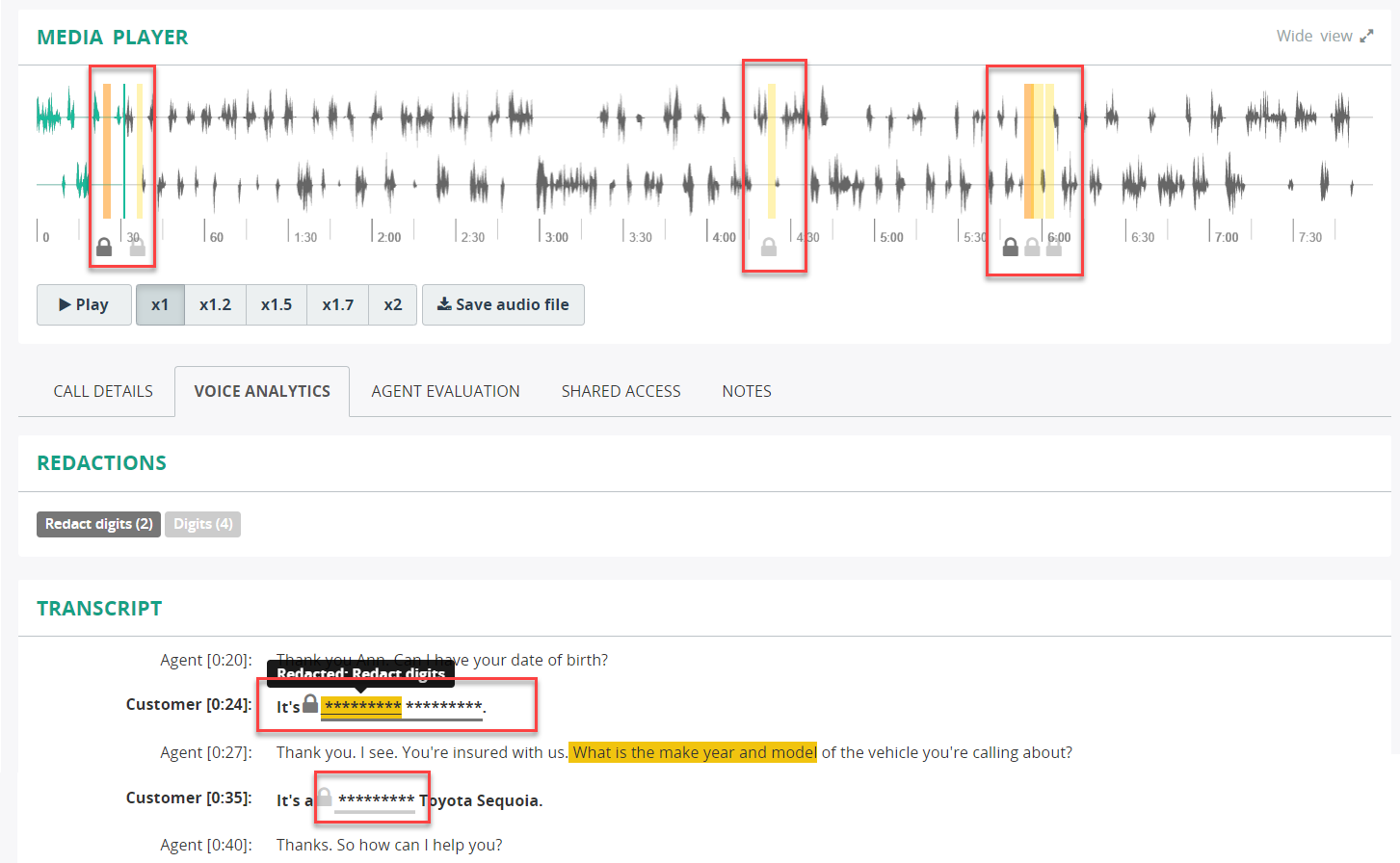
About Data Redaction
Redaction is used to remove sensitive content from the transctipts and audio recordings. For example, you can use data redaction to eliminate or mask sensitive personal information such as credit card numbers, phone numbers, or dates of birth from call recordings.
MiaRec data redaction engine relies upon the use of redaction rules to locate text in transcripts to redact (see MQL Reference Guide). Data is redacted from both transcripts and the associated audio files.
Important
The redaction feature is designed to identify and remove sensitive data. However, due to the predictive nature of machine learning (i.e. transcription) and the variability of human language, MiaRec Data Redaction may not identify and remove all instances of sensitive data in your transcripts and recordings.
Since both false positive and false negative errors can occur, it is important to understand how both types of errors might affect your overall system. False negatives could lead to personal information leakage. False positives could lead to non-sensitive data being recognized as sensitive and thus redacted.
We strongly recommend that you review any redacted output to ensure it meets your needs.
How to Apply Data Redaction: Best Practices
- Create a set of redaction rules and test them on a few individual recordings.
- Use advanced search criteria (on the Recordings > Advanced Search page), and find recordings in your platform that represent good candidates for redaction, for example, if you target calls with credit card number information, then search by words "credit card" or even just words "card" or "number". Tag those recordings as a testing dataset with a custom tag, for example, "test-redaction".
- Run a job in a test mode (highlight only) on the recordings that were selected for testing.
- Review the highlighted results and fine-tune the redaction rules as necessary.
- Once the results are satisfactory, configure a job to run periodically in production mode.
- Periodically, do a manual spot check if the redaction rules are still applicable to a new vocabulary that agents may use in conversations.